AI Agents & Development Timeline
Here's some of my explorative technologies and insights into AI. I believe I am making information assistants, not artificial intelligence.


Here's some of my explorative technologies and insights into AI. I believe I am making information assistants, not artificial intelligence.
- In 2021, I first started Sentiment Analysis on news articles using IBM Watson and Apify. This enabled me to understand how basic text analysis, API calls, processing on servers and LLM's architecture works. The costs were quite reasonable and at that time IBM Watson had an easy to use API pipeline. I didn't even know about OpenAI or ChatGPT.
- 2023 I was part of the global user base realizing the power of the transformer and ChatGPT. When I realized these LLM's were trained on Wikipedia and social media I knew conventional intellectual property systems would not protect users. I started to silo and protect our company databases, bilingual parallel high-quality datasets from scraping.
- In 2022, our non-profit, granted two AI research groups access to a fraction of our bilingual data which they used to develop orthography tools and text-to-speech. Wow! These tools are helpful. Our AI partners are aligned on our values and outcomes.
- In 2023 I spoke at the International Conference on Machine Learning in Honolulu with a colleague on the cultural and ethic importance of respecting the provenance of indigenous language data. Other views at the time are fatalist and progressive. While respectful, they believe the ethnical position is not tenable due to rapid progress, diversity in AI researcher ethics and disruptive data gathering tech. But our AI partners benchmarks totally smashed OpenAI and Microsoft projects out of the park. Small scale, highly tuned models and LLM's work - really well.
- I explore AI agents and find this excellent agent coded on GitHub. It creates sub-tasks with amazing ability. Wow!
- I am using Codieum to write code. Helpful for searching web - agentic use.
- By now late 2023, I had become a power user of Claude, ChatGPT, Perplexity. I was perpetually troubled by my data storage and these large corporations fine-tuning their next iteration on user logs. At scale, this amplifies inequalities between LLM frontier companies and individual users. We need something private and protected for small scale use.
- I download Windsurf, Cursor, Bolt and try Loveable. Vibe coding is fun. I create my local sports club website in 2 hours on Windsurf. I become a foundation subscriber of Windsurf. Check out club website here.
- In late 2024 I downloaded LM Studio and understood the capabilities of open source LLM's on edge devices (my laptop). This led me to realize that smaller models are dumb (for my interest areas) and inaccurate. Their knowledge box is small; contextualization and synthesis abilities are curtailed by whatever data they have to work with. I understand that 'grounding' these skilled LLM with better primary source material, or, updated relevant local information from the web is critical to improving their adoption and use.
- In early 2025 this led me to study MCP, model context protocol. I tested this technology by adding MCP functionality to my Claude OS native app using Perplexity Sonar Pro MP integration and a local file. Very easy and very helpful. Drastically improved Claude 3.7 Sonnet results.
- By now I am creating lots of protoypes on Windsurf. I notice massive ability variation between models. The researching GitHub repositories for issues and workarounds is 🔥. Loving Windsurf. But then it totally fails for 2 days and I am using Cursor and VS Code GitHub CoPilot.
- March 2025 while simultaneously testing OpenAI 'Deep Research' and DeepSeek R1, I realised that the expanded logic thought processing was as equally helpful as the results. However their answers differed widely. This variance in outcomes was something that needed to be mitigated against. These are clearly agentic systems but embedded inside an LLM.
- A friend of mine, had developed a Tax Agent using Dify and his own propritary tax databsase. He showed me and I liked it. I explored Dify and n8n as workflows.
- April I make my first Dify app using my own Prompt engineering and Knowledge base. It's enough to give me an idea of what is possible with more grounding.

- I hypothesize that multi-model or multi-agent approach is wiser, like a team of advisors or experts. I research papers on Mixture of Agents. I make my second AI agent on Dify, which I super creatively name "Mixture of Agent" 🤷 🤦. It performs well, slowly but the results lead me into more prompt engineering with Gemini 2.5 Pro.
- Seeking more grounding, I add Perplexity Sonar Pro based on my original MCP demo and continue prompt engineering. I call this option "4i 1o", meaning four AI in and one AI out. The "4i" input refers to how many models are providing opinions or advice, in this case four, and the 1o means one LLM is synthesizing and aggregating the output according to my prompts. I am very happy with this.
- I release 5i 1o (Gemini 2.5 Pro as the final aggregator: Try it here. My best effort yet and a design I use daily for information gathering. Just needs more precise grounding.
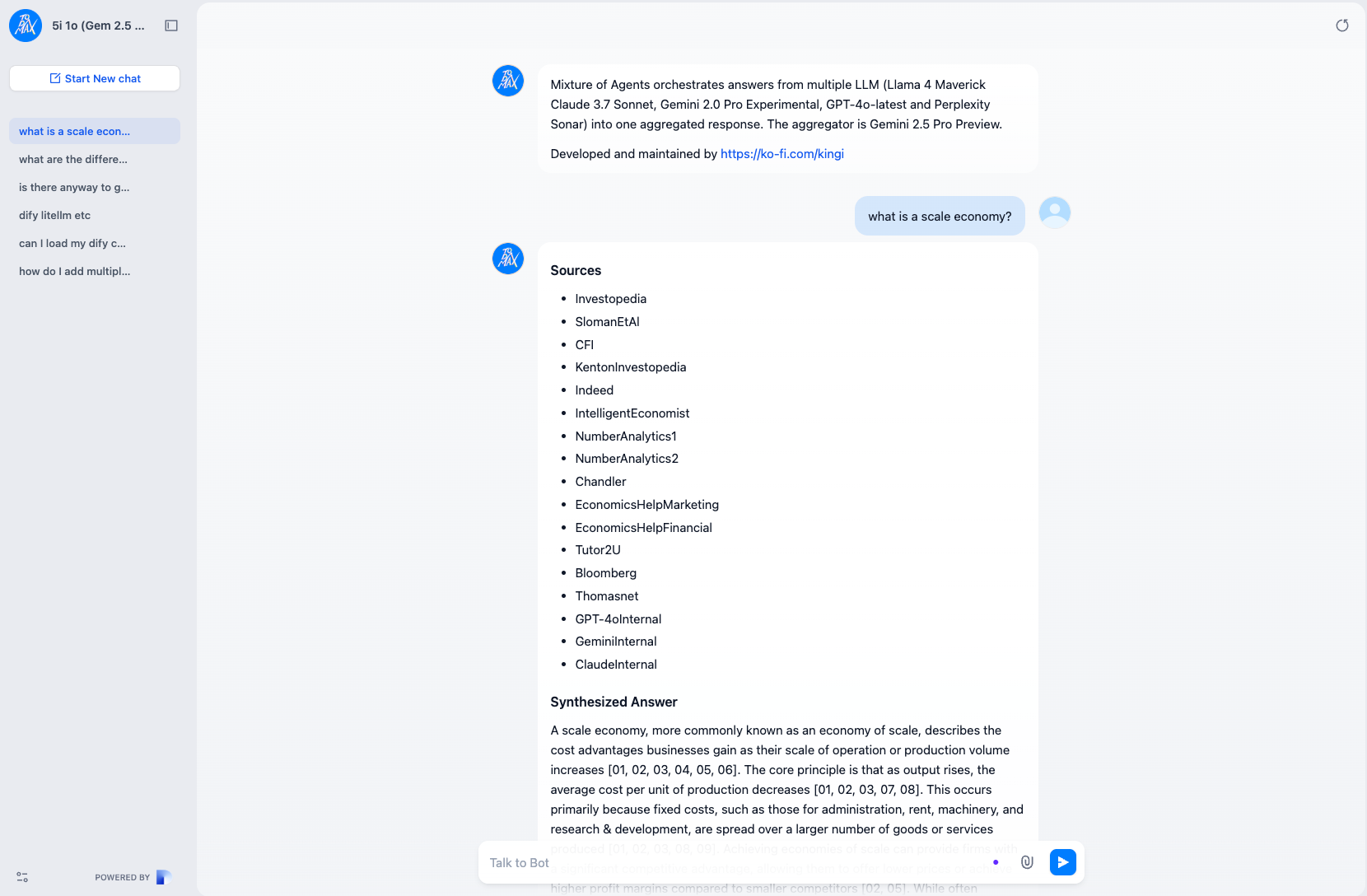
- I continue to scale with the new prototype, 5i 3o. You guessed it. I add evaluators and advisors to the back-end, using the two more sophisticated reasoning models - Gemini 2.5 Pro and Claude 3.7 Sonnet. I am disappointed with the results. I work on prompt engineering and notice a wide variation in LLM capability from current top available models (April 2025). I evaluate long context synthesis from more than five LLM. The last stage aggregator and summarizer LLM struggles with the layered deepness. I decided to shelve this approach for now.
- Explore fine-tuning my own LLM using Llama 3B with knowledge from my own logs and some other data I need to find on synthesis. I'm on together.ai and exploring the cost to fine-tune. Wait, this is still a hobby right?
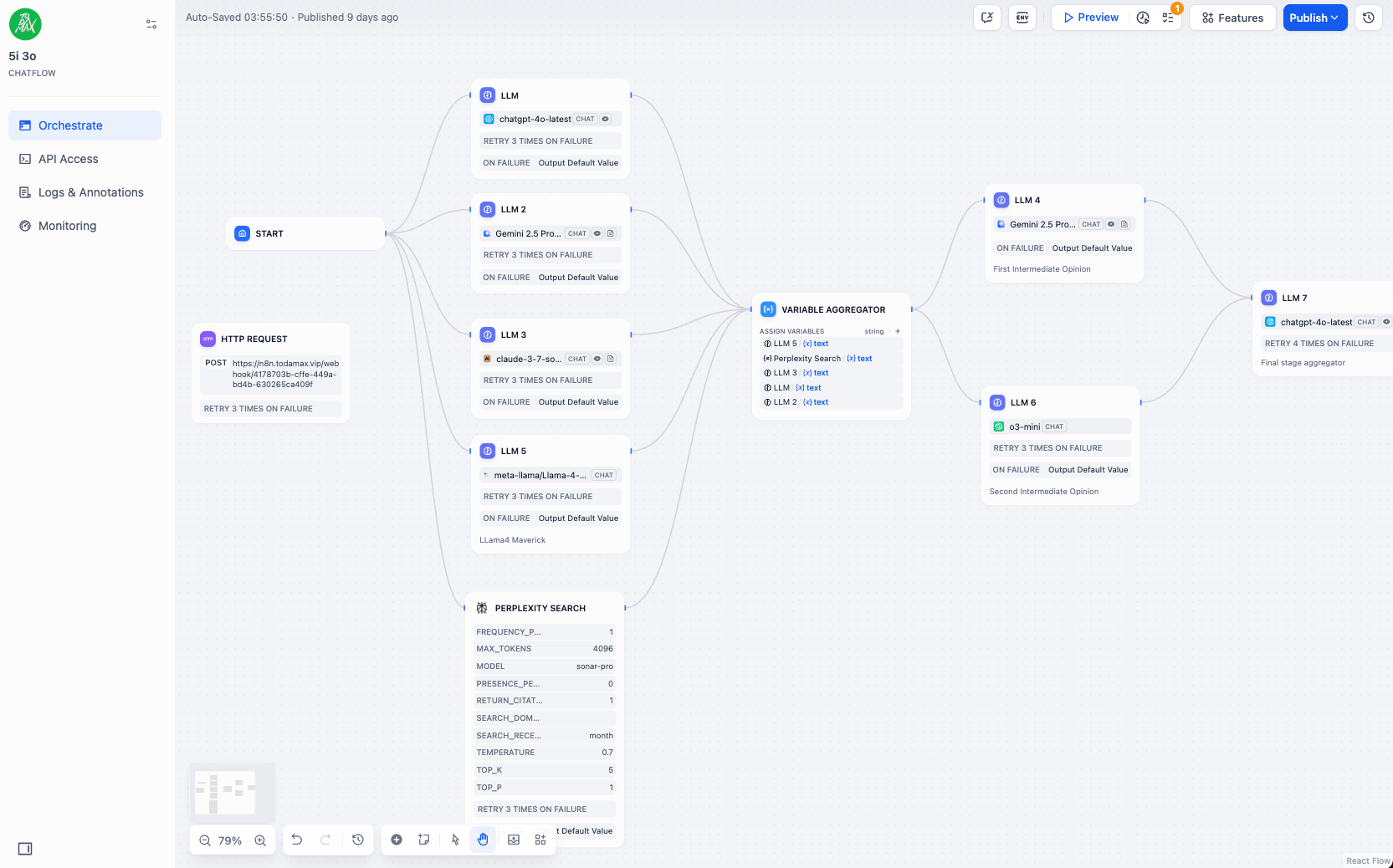
- I set-up my own online server running Ollama, OpenWebUI, LiteLLM. It runs here https://ai.todamax.vip/ - I have some form of data sovereignty, problem is I still need to call these frontier hosted corporate LLM's. Ok so if we are going to be in a perpetual dance, then I need to figure out how to keep true to the values I believe in. Open source. User privacy by default. Information empowers equity. What should I trade with the corporations? Logs I guess. Here's my spend on models to date.
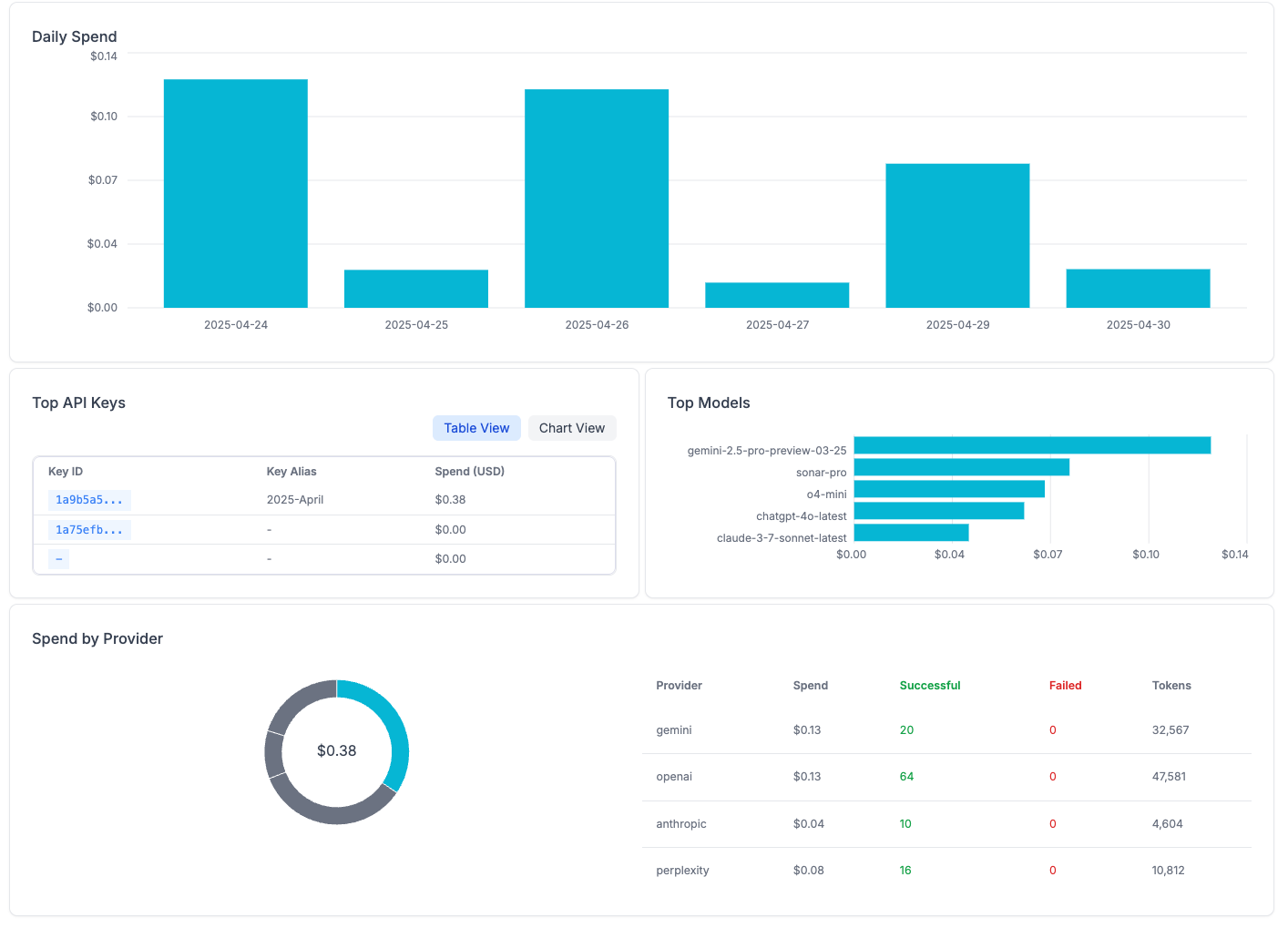
- Exploring Jina.ai as a grounding approach and weighting the grounded data earlier into the process. My design is
4i → 1g → 2r → 1s
Four in → one grounding pass → two reviewers → one summarizer
Lower generation and lower cost models such as Nano-4.1 sit at the raw gathering end, high quality latest models sit at the middle and the best language explaination model with largest effective context window are the final step. I may need to fine-tune both evaluator-advisors and final stage synthesizers. Hmmm...
- The key target for me as of 1 May 2025 is effective context window and reasoned grounding. These are the key phases in the data gathering process that eliminate crap data and minimize the junk stored in context. Refine the data first before looking for gold. Try and make sure the data filtering process isn't removing gems.